If you want to develop modules or plugins for spmfilter, you need to understand how spmfilter is processing an email.
The processing chain is relatively simple, at first the engine is loaded, either smtpd or pipe, afterwards begins the processing of the registered modules.
The return code of the module decides further processing. This makes it possible, to control whether following modules should be started or not. If the return code of all modules is 0, the email will be delivered to the final destination.
Every module can return one of the following codes:
| code | description |
|---|---|
| -1 | Error in processing, spmfilter will send 4xx Error to local MTA |
| 0 | All ok, the next plugin will be started. |
| 1 | Further processing will be stopped, no other plugin will be startet. spmfilter sends a 250 code. E-Mail is not going to be delivered to nexthop! |
| 2 | Further processing will be stopped, no other plugin will be startet. spmfilter sends a 250 code. E-Mail will be delivered to nexthop |
If the return value of the plugin is greater or equal than 400, then the value is used as smtp response code, as defined in spmfilter.conf.
If for example an error occurred within a plugin, then all the previous plugins are not automatically re-processed. Spmfilter uses so-called "state-files" to store the current state of the processing chain. Each plugin, which was successfully executed, will be held here, in case of an error they won't be processed again. Each "state file" has an unique name, which is computed from the message ID. In this way spmfilter is able to check the previous processing state. The "state file" will be removed, if the last plugin was processed successfully.
Since each plugin is a dynamic shared object, it must provide a specific entry point, which is called by spmfilter. The entry point in the plugin is called immediately after spmfilter loads the plugin. This entry point is only called once during the execution. In calling the plugin, the first argument is a SMFSettings_T instance, that contains the configuration of the spmfilter. The second argument passed to the plugin is a SMFSession_T object, which holds all session informations.
The call is:
Check smf_modules.h for more information of the module-interface of spmfilter.
Compiling
To compile a spmfilter module, you need to tell the compiler where to find the spmfilter and libcmime header files and libraries. This is done with the pkg-config utility. The following interactive shell session demonstrates how pkg-config is used (the actual output on your system may be different):
Datatypes
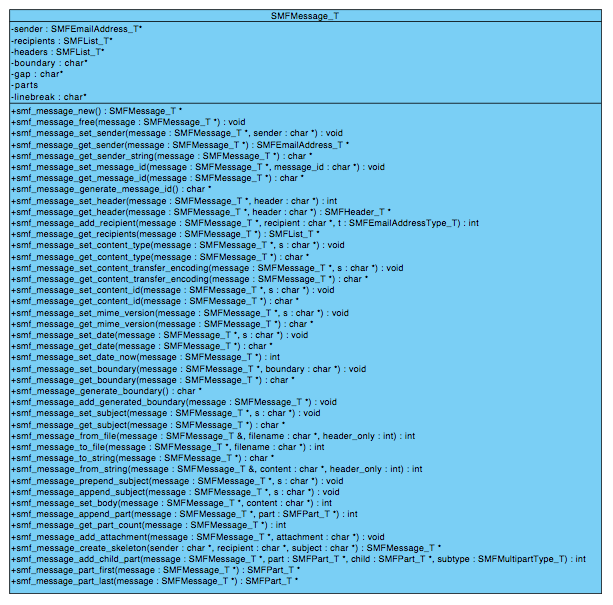
Spmfilter uses a bunch of custom datatypes. The following image will give you a overview of all datatypes and their dependencies.

Sessions
All session data is stored in a SMFSession_T object by spmfilter, whereas the email content is stored on disk instead, but connection informations and message headers are hold in memory. If you need to modify an email in the current session, you have to use the session functions.
If a header of a session object has been modified, the session will be marked as "dirty" - that means the header will be flushed to disk before the final delivery is initialized, to keep the message in sync with the modified data. In contrast to the session functions, the message functions are used to generate new messages which are hold in memory only.
Spmfilter also tracks the modification time of the spool file in the session. When a module modifies the spool-file (e.g. appends content to the message-body), then the changes are merged with the session and are made available for all subsequent module-invocations.
Please note that not all session variables in each configuration are available. For example, all SMTP related data is not available in the pipe engine.
Generally available data:
- session id
- spool file
- message size
- message envelope (SMFEnvelope_T)
Additional with smtp engine available:
- transmitted smtp helo/ehlo name
- transmitted smtp xforward address (only if MTA is configured to do so)
Within one SMFSession_T object a SMFEnvelope_T object is encapsulated, containing the envelope information of a mail.

Messages
Each incoming messages is automatically parsed by spmfilter. All message data is stored within a SMFMessage_T object. If you are using the smtpd engine for receiving mails, the smtpd session data is stored within a SMFEnvelope_T object. Please note, that the message body and all mime parts of an incoming message is not stored within a SMFMessage_T object, since possible attachments should not be hold in memory. If you need access to all mime parts, you have to reparse the spool file with smf_message_from_file().
Lookups
Spmfilter implements a small, fast, and easy to use database API with thread-safe connection pooling. The library can connect transparently to multiple database systems, has zero configuration and connections are specified via a standard URL scheme. Supported are variety of database systems:
- MySQL
- PostgreSQL
- SQLite
- Berkeley DB
- LDAP directories.
Spmfilter cares completely around connection management, load balancing and fallback connections. Failed connections will be also reconnected again automatically.
Whether you are using a SQL database or a LDAP directory, all results are delivered as SMFList_T objects back. This is a kind of singly linked list for all found SQL rows or LDAP entries. Each element is a SMFDict_T object, which is implemented as a dictionary, in which each key represents a SQL column or a LDAP attribute.
The only exception here is Berkeley DB, as this does not require a query language and is based on key/values.
In order to use database lookups, you have to set a backend in spmfilter.conf, this can be sql or ldap. If a valid backend is configured, spmfilter will automatically establish the connection.